Vision & motivation
Les plateformes de données financières commerciales — Bloomberg, Refinitiv, Quandl — sont puissantes mais coûteuses, fermées et non maîtrisables. Mon objectif était de construire une infrastructure personnelle souveraine : une source de données financières unique, fiable et sécurisée, qui serve de socle à tous mes futurs projets quantitatifs.
StockStream n’est pas un simple dashboard de visualisation. C’est une API financière privée, pensée dès le départ pour être consommée par d’autres applications. Un backend qui tourne en continu, collecte et historise cours, fondamentaux, données analytiques et événements de marché, et expose tout cela via des endpoints REST sécurisés par token.
L’idée centrale : plutôt que de ré-implémenter l’accès à Yahoo Finance — avec ses contraintes de rate-limit, sa détection de bots et sa gestion des erreurs — dans chaque futur projet, je centralise toute cette complexité une seule fois. Les projets consommateurs font des appels REST simples et reçoivent des données propres, déjà stockées, déduplicquées et historisées.
Architecture
L’application repose sur un stack monolithique léger, déployable avec une seule commande.
| Couche | Technologie |
|---|---|
| Backend | Python 3.12, FastAPI, SQLAlchemy 2 async, asyncpg |
| Frontend | React 19, TypeScript strict, Vite, CSS variables |
| Données de marché | yfinance + curl-cffi |
| Infrastructure | Docker multi-stage, uv, PostgreSQL 16, pgAdmin |
| Temps réel | WebSocket (log stream + métriques live) |
Trois services Docker : stockstream (8000), postgres (réseau interne), pgadmin (7999). Le backend expose l’API REST sous /api et sert les fichiers statiques React depuis le même process — pas de reverse proxy supplémentaire.
Les services partagés (base de données, moteur de sync, scheduler, log broker) sont centralisés dans un service locator statique CONTEXT, accessible depuis toutes les couches sans injection de dépendances globale.
Démarrage en 7 étapes (lifespan FastAPI) : banner + config → configuration yfinance → initialisation DB → bootstrap du token root JWT → démarrage du cron scheduler → setup du broker de logs WebSocket → initialisation de l’état runtime.
Données financières collectées
StockStream couvre l’ensemble de la surface de données exposée par Yahoo Finance, organisée en plusieurs couches stockées séparément.
Données de prix (OHLCV)
Chaque actif dispose de sa propre table dynamique en base, nommée selon son type : equity_42, etf_7, fx_3, composed_1. Cette approche évite les tables monolithiques à millions de lignes croisées. Les insertions utilisent un upsert natif (ON CONFLICT DO UPDATE) pour garantir l’idempotence — relancer une synchro ne crée jamais de doublons.
Types d’actifs supportés :
- Actions (equity) — toutes places boursières accessibles via Yahoo Finance
- ETFs — fonds indiciels et thématiques
- Cryptomonnaies
- Paires de devises (FX) — base/quote configurable, table
fx_<pair_id> - Indices composés — indices synthétiques construits comme combinaison pondérée d’actifs existants
Granularités disponibles : 1m, 2m, 5m, 15m, 30m, 60m, 90m, 1h, 1d, 5d, 1wk, 1mo, 3mo.
Métadonnées historisées
À chaque synchronisation, les métadonnées de l’actif (secteur, industrie, capitalisation boursière, nombre d’employés, description, etc.) sont comparées à la version précédente. Seules les différences (deltas) sont enregistrées dans la table MetadataSnapshot. Cela permet de retracer l’évolution d’un actif dans le temps sans stocker de doublons.
Données fondamentales
Les états financiers complets sont collectés et stockés : compte de résultat, bilan, flux de trésorerie — en annuel et trimestriel. Chaque entrée est associée à un hash de contenu pour détecter les révisions sans re-stocker de données identiques.
Données analytiques & couverture de marché
- Recommandations d’analystes : consensus (Strong Buy / Buy / Hold / Sell / Strong Sell), évolution historique du consensus
- Price targets : médiane, bas, haut, nombre d’analystes couvrant la valeur
- Estimations de revenus et d’EPS : par trimestre et par année, avec les valeurs attendues vs réalisées
Calendrier des événements
- Earnings dates : prochaines dates de publication des résultats, EPS attendu, EPS réalisé
- Dividendes : dates ex-dividende, montants, fréquence
Scores ESG & durabilité
Scores environnementaux, sociaux et de gouvernance, niveau de controverse, comparaison par rapport au secteur et à l’industrie.
Positions des investisseurs
- Institutionnels : top holders, pourcentage détenu, évolution trimestrielle
- Insiders : transactions déclarées (achats/ventes) des dirigeants
- Fonds communs : top fonds détenteurs
Moteur de synchronisation
Architecture async
Le moteur de synchronisation est entièrement asynchrone. Chaque job de sync est une tâche asyncio indépendante, trackée dans un dictionnaire runtime sync_tasks. Les appels yfinance (bloquants par nature) sont isolés dans asyncio.to_thread() pour ne jamais bloquer l’event loop.
Un job de sync peut couvrir plusieurs étapes : prix OHLCV → métadonnées → états financiers → données analytiques → holders → événements. Si une étape échoue, le job passe en statut partial (succès partiel) plutôt qu’en failed — les données correctement collectées sont conservées.
Cron Scheduler
Chaque actif peut avoir une ou plusieurs règles de planification associées. Le scheduler tourne en boucle de 20 secondes et gère automatiquement :
- Déclenchement des crons échus : les jobs sont lancés en parallèle selon leurs schedules
- Auto-désactivation : si l’actif cible d’un cron a été supprimé, le cron est désactivé automatiquement
- Détection des orphelins : les crons dont la cible n’existe plus en base sont identifiés et peuvent être supprimés en batch
- Traitement
partialcomme succès : un job partiellement réussi ne bloque pas la prochaine planification
Robustesse réseau & contournement des restrictions
Yahoo Finance bloque les clients détectés comme bots. Pour garantir la fiabilité de la collecte :
Rotation de profil navigateur — à chaque appel yfinance, une nouvelle session curl-cffi est créée avec un profil navigateur différent, sélectionné parmi 5 profils supportés : chrome136, chrome133a, safari18_0, chrome131, edge134. Chaque appel simule un navigateur légitime différent.
Probe au démarrage — au lancement, chaque profil est testé contre l’API Yahoo Finance. Les profils non supportés par l’environnement (réseau, OS) sont auto-exclus de la rotation.
Retry exponentiel — en cas d’erreur réseau transitoire, 3 tentatives avec backoff 4s → 8s avant de marquer le job en échec.
Proxy optionnel — support d’un proxy HTTP configurable dans yfinance_config.yaml (network.proxy_url), pour router les requêtes via un point de sortie différent si nécessaire.
Authentification & gestion des accès
C’est l’une des composantes les plus importantes de l’architecture : StockStream étant la source de données centrale de tous mes projets financiers futurs, la gestion des accès est traitée avec le même soin qu’une API de production.
Tokens JWT porteurs
Chaque client — qu’il soit une application tierce, un notebook, un service de backtesting — s’authentifie avec un token JWT porteur. Les tokens sont :
- créés depuis le dashboard avec un nom, une description et une date d’expiration optionnelle
- révocables à tout moment : la révocation prend effet immédiatement sur toutes les requêtes suivantes
- scopés par permissions granulaires : chaque token est associé à un ensemble de permissions par domaine et action
Système de permissions
Les permissions suivent un schéma domaine.action avec support des wildcards :
assets.read → lecture des actifsassets.write → création/modificationassets.* → accès complet au domaine assetscron.readjobs.readauth.read* → accès root completUn token émis pour un service de backtesting peut avoir uniquement assets.read et jobs.read, sans aucun accès aux fonctions d’administration. Cela limite la surface d’exposition en cas de compromission d’un token.
Token root au bootstrap
Un token root est automatiquement bootstrappé au premier démarrage (configurable via API_AUTH_ROOT_TOKEN_ID). Ce token a les permissions * et sert à créer les premiers tokens applicatifs depuis l’interface.
Audit log complet
Chaque requête authentifiée est enregistrée en base : token utilisé, endpoint, méthode HTTP, statut de réponse, timestamp. L’audit log est consultable depuis le dashboard et sert de base aux analytics d’usage.
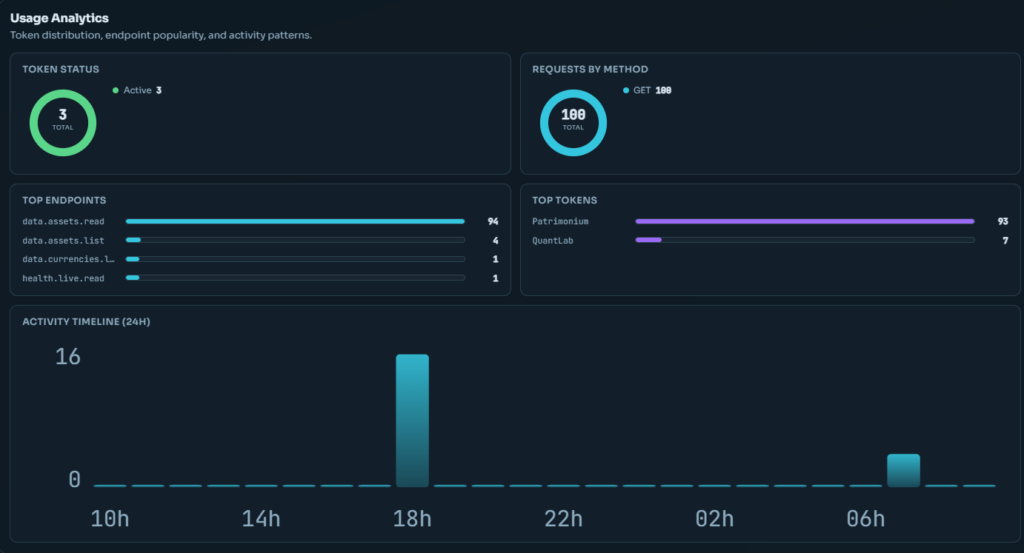
Usage Analytics
Le panneau Auth expose 5 visualisations en temps réel sur l’activité de l’API :
- Donut Statuts : distribution des codes de réponse (2xx / 4xx / 5xx)
- Donut Méthodes : répartition GET / POST / PUT / DELETE
- Barre Top Endpoints : les endpoints les plus appelés
- Barre Top Tokens : les tokens les plus actifs
- Histogramme 24h : activité heure par heure sur les dernières 24 heures
Interface — Data Explorer

L’explorateur de données est l’interface principale pour naviguer dans les actifs collectés.
Navigation par catégorie
Au chargement, seuls les compteurs par catégorie sont récupérés via un endpoint dédié (GET /assets/categories) — instantané, sans charger aucun actif. Chaque catégorie (EQUITY, ETF, CRYPTO, FX, COMPOSED…) s’expand en lazy-loading au premier clic : 50 actifs par page, avec une barre de recherche par catégorie (debounce 350ms) et un bouton « Charger plus ».
Détail d’un actif
Le panneau de détail d’un actif s’organise en onglets :
Prix — graphique OHLCV interactif avec sélection de timeframe, zoom, indicateur de volume. Conversion de devise intégrée : le sélecteur n’affiche que les devises atteignables via les paires FX réellement stockées en base (pas une liste statique). Une barre d’avertissement orange s’affiche automatiquement si la granularité de l’actif est plus fine que la meilleure paire FX disponible.
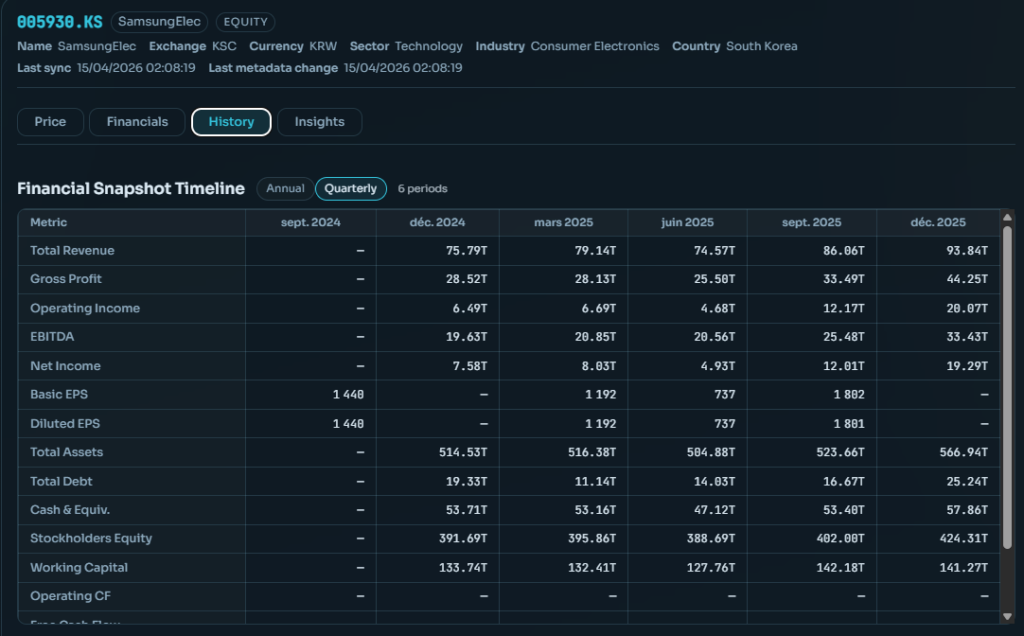
Fondamentaux — états financiers historiques (compte de résultat, bilan, flux de trésorerie) tabulés par période.
Historique — timeline des deltas de métadonnées : chaque changement de valeur (capitalisation, secteur, nombre d’employés…) est affiché avec la date, l’ancienne valeur et la nouvelle valeur.
Insights — onglet chargé en lazy au premier clic, agrège toutes les données analytiques et fondamentales :
- Tableau des recommandations d’analystes avec évolution historique
- Price targets (médiane, fourchette, nb analystes)
- Estimations de revenus et d’EPS
- Calendrier des earnings et dividendes (cards)
- Scores ESG et durabilité (cards)
- Tables des institutionnels, insiders et fonds communs
Interface — Overview Dashboard

Le dashboard principal donne une vue transversale en temps réel de tout le système.
System Monitoring
Métriques globales en temps réel via WebSocket : nombre d’actifs, de paires FX, de jobs actifs/complétés/en erreur, nombre de crons actifs, pool de connexions DB. Graphique d’activité des jobs sur les 7 derniers jours.
Asset Coverage — Donut interactif
Distribution des types d’actifs représentée par un donut cliquable. Un clic sur un segment (ou sur un chip de légende) ouvre une modale listant tous les actifs de ce type, avec barre de recherche et suppression individuelle par actif.
Recent Jobs
Tableau des derniers jobs de synchronisation avec :
- Filtre par statut (All / Running / Completed / Partial / Failed)
- Recherche par symbole
- Tri sur toutes les colonnes (Asset, Timeframe, Lancé, Durée, Statut, Records)
- Pagination « Load more »
- Clic sur un job en échec → ouverture de la modale de détail complète (logs d’erreur, contexte)
Errors & Health
Panneau dédié aux jobs en échec et aux erreurs de crons. Dismiss individuel (×) par ligne ou dismiss batch (« Clear all »). Retry batch pour relancer tous les jobs en échec en un clic. Clic sur une erreur → modale de détail.
Cron Monitoring
Vue de tous les crons actifs avec recherche par nom ou symbole cible. Toggle « upcoming only » pour n’afficher que les crons qui vont se déclencher prochainement. Prochaine exécution calculée et affichée.
Coverage & Gaps
Section de diagnostic actif de la santé des données :
| Section | Description |
|---|---|
| Never Synced | Actifs créés mais jamais synchronisés |
| Stale Assets | Actifs dont la dernière synchro dépasse un seuil configurable (1/3/7/14/30 jours) |
| No Cron Attached | Actifs sans règle de planification — ne seront jamais re-synchronisés automatiquement |
| Duplicate Crons | Actifs ayant plusieurs crons actifs sur le même timeframe |
| Orphan Crons | Crons dont l’actif cible n’existe plus en base |
Chaque section dispose d’actions batch : « Sync all », « Sync all stale », « Delete all orphans ». Actions individuelles par ligne également.
Token Monitoring
Tableau de l’usage des tokens API avec pagination load-more. Volume de requêtes par token, dernier appel, statuts agrégés.
Interface — Sync Engine Monitor

Panneau de monitoring en temps réel du moteur de synchronisation, mis à jour via WebSocket.
Auto Lancer — indicateur d’état du moteur (running / stopped), nombre de jobs en cours, slots concurrents utilisés / disponibles.
DB Connection Pool — visualisation de l’état du pool asyncpg : connexions actives, oisives, en attente. Indicateur de saturation.
Sync Job Slots — grille visuelle des slots de jobs concurrents, avec statut de chaque slot (idle / running / error). Statistiques : jobs en cours, en attente, complétés, échoués, max simultanés, dernier request.
Le panneau se met à jour en temps réel sans rechargement — idéal pour surveiller une vague de synchros batch.
Interface — Cron Optimizer
Interface dédiée à la gestion des règles de planification. Création, édition, suppression de crons avec expression cron configurable. Vue calendrier des prochains déclenchements. Détection des conflits de planification (plusieurs crons sur le même actif/timeframe). Bouton « Run now » pour déclencher manuellement un cron sans attendre son prochain cycle.
Interface — Logs temps réel
Flux de logs en direct via WebSocket, avec filtrage par niveau (DEBUG / INFO / WARNING / ERROR) et par module. Bouton pause/resume et clear. Le broker de logs est branché directement sur le système de logging backend (loguru) — tous les logs de tous les services (moteur de sync, crons, DB, yfinance) sont streamés en temps réel dans l’interface.
Design & responsive
L’interface est entièrement responsive avec trois breakpoints :
| Breakpoint | Comportement |
|---|---|
| ≤ 1080px (tablette) | Engine Monitor passe en 2 colonnes, sidebar réduite |
| ≤ 600px (mobile) | Explorer : sidebar masquée quand un actif est sélectionné, bouton ← Retour. Onglets en scroll horizontal. Logs full-width. |
| ≤ 400px (petit mobile) | Grilles passent en 1 colonne, cartes en pleine largeur |
Le pattern has-selection sur l’Explorer mobile permet de naviguer dans les actifs sans jamais avoir les deux panneaux superposés.
StockStream comme hub de données — vision multi-projets
L’architecture token + permissions n’est pas anecdotique : elle prépare concrètement l’intégration de projets futurs. Chaque nouveau projet financier que je développe reçoit son propre token scoped, et consomme les données via l’API sans jamais toucher ni la base ni la couche de collecte.
Projets envisagés en s’appuyant sur StockStream :
- Backtesting de stratégies : service Python qui tire les séries OHLCV via
GET /assets/{id}/priceset simule des stratégies sans gérer l’accès aux données - Système d’alertes : service léger qui interroge les prix et consensus analystes sur seuils configurables (price target franchi, révision du consensus, earnings imminent)
- Dashboard de portfolio : suivi de positions personnelles enrichi avec données fondamentales, événements de calendrier et scores ESG — tout via l’API
- Analyse quantitative : notebooks Jupyter qui utilisent l’API comme source de données, avec conversion de devise et granularité au choix
- Modèles prédictifs : features engineering alimenté par les séries temporelles et les données fondamentales historisées
Cette approche reflète une philosophie d’architecture que j’applique à l’ensemble de mes projets financiers : une source de vérité unique, exposée proprement, consommée par des services spécialisés.
Résultats & recul technique
StockStream tourne en production sur mon infrastructure personnelle depuis plusieurs mois, collectant en continu des données sur plusieurs centaines d’actifs.
Les points techniques les plus significatifs du projet :
- Zéro interruption de collecte grâce au moteur async, à la gestion des erreurs partielles et au retry exponentiel
- Déduplication hash-based à chaque niveau (prix, métadonnées, données analytiques) — relancer une synchro est toujours safe
- Isolation des données par actif (tables dynamiques) — les requêtes sur un actif n’impactent jamais les performances sur les autres
- API de production dès le premier jour : auth, permissions, audit, analytics — pas ajouté en retard
Ce projet m’a permis de traiter des problèmes rarement abordés dans des tutoriels : contournement de détection de bots à l’échelle, gestion de synchros partielles dans un système distribué, architecture multi-tenant légère avec un seul service.