
Exploitation des Données de Marché Haute Fréquence via un Modèle Transformer : Une Approche Quantitative Avancée
Ayant récemment développé une passion en finance quantitative et en apprentissage automatique appliqué aux marchés financiers, j’ai décidé de relever un défi exigeant en participant au concours « High Frequency Market Data: Could You Guess the Stock? » organisé par Capital Fund Management (CFM) dans le cadre du Challenge Data de l’ENS. Ce projet m’a permis de combiner des compétences avancées en traitement de données massives, modélisation statistique et deep learning, en particulier via l’implémentation d’un modèle Transformer, architecture phare des Large Language Models (LLM) et désormais de plus en plus utilisée pour la modélisation des séries temporelles complexes.
Phase 1 : Prétraitement et Analyse Exploratoire des Données
L’ensemble de données fourni consistait en des séquences de 100 actions effectuées sur un même actif financier. Le désalignement des dimensions entre les matrices d’entrée (X_train) et la variable cible (y_train) nécessitait une transformation préalable, notamment via une duplication et agrégation des observations pour garantir une cohérence structurelle.
Nettoyage et Transformation des Données
- Détection des valeurs aberrantes : Vérification de la qualité des données via des méthodes statistiques (test de Kolmogorov-Smirnov, analyse des distributions empiriques).
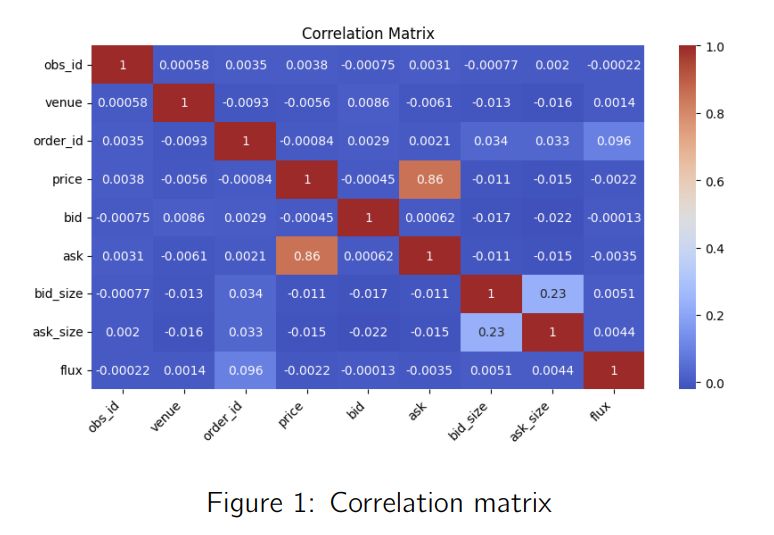
- Analyse des corrélations : Matrice de corrélation Pearson révélant une multicolinéarité élevée, notamment entre ask et price (> 86%), suggérant une possible réduction de dimension.
- Encodage des variables catégoriques : One-hot encoding pour les attributs discrets (ex. venue, action).
- Feature Engineering avancé :
- Construction de features agrégés : mean price, variance price, median spread, bid-ask spread, buy/sell ratios.
- Normalisation par MinMax Scaling et RobustScaler pour préserver la structure des distributions.
- Application de Principal Component Analysis (PCA) pour observer la représentabilité des features dans un espace latent réduit.
Phase 2 : Approche Baseline et Méthodes d’Ensemble Learning
Après prétraitement, j’ai implémenté plusieurs modèles supervisés classiques pour établir une base de comparaison :
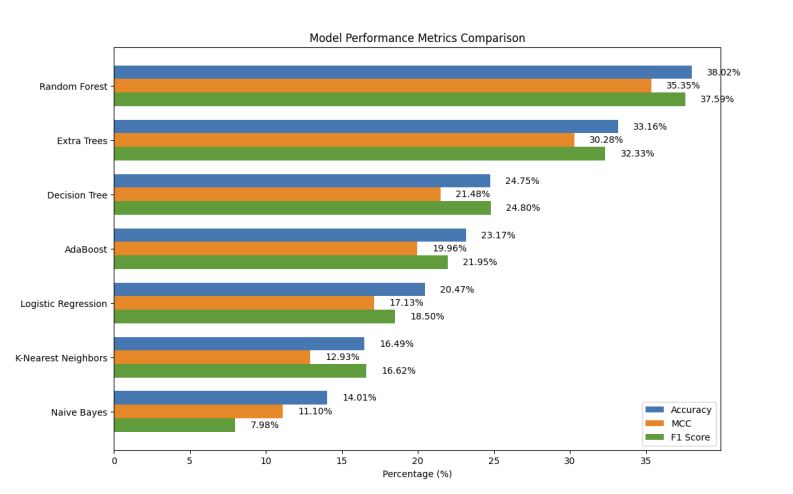
Modèles dérivés du Random Forest (meilleur modèle d’après mon premier test comparatif). Ces modèles ont été optimisé par sélection des bons hyper-paramètres d’où la nette amélioration de leur score.
- Logistic Regression : Incapable de capturer les relations non linéaires, limité à 20.47% de précision.
- K-Nearest Neighbors (KNN) : Fortement pénalisé par la curse of dimensionality, avec une performance de 16.49%.
- Decision Tree : Tendances à l’overfitting, avec 24.75% de précision.
- Random Forest : Meilleur modèle baseline (38.02%), mais limité par une consommation mémoire importante.
- Gradient Boosting (XGBoost, LightGBM) : Approches plus robustes exploitant des mécanismes de bagging et boosting.
Optimisation des hyperparamètres
J’ai utilisé Optuna, une bibliothèque d’optimisation par recherche bayésienne, pour affiner les hyperparamètres clés de LightGBM :
- Nombre d’arbres optimisé (n_estimators) : Augmenté progressivement jusqu’à convergence.
- Depth tuning : Test de différentes profondeurs pour limiter l’overfitting.
- Feature selection automatique : Suppression des features redondants impactant la généralisation.
Techniques d’ensemble learning
Pour améliorer la robustesse des modèles, j’ai testé plusieurs méthodes d’ensemble :
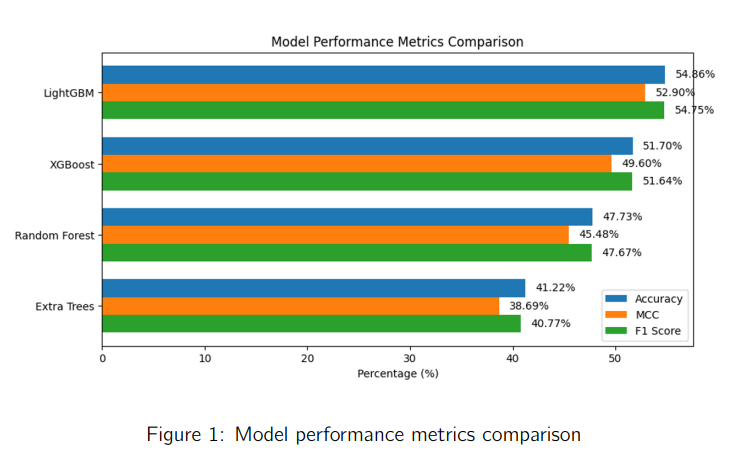
- Bagging avec LightGBM (Meilleur résultat : 55.74% de précision).
- Stacking avec XGBoost + LightGBM + Random Forest (gain marginal, mais meilleur équilibre biais-variance).
- Hard Voting (méthode la plus rapide mais légèrement sous-optimale).
Phase 3 : Implémentation d’un Transformer pour la Modélisation des Séries Temporelles
Les limitations observées sur les modèles basés sur arbres de décision m’ont conduit à tester une approche radicalement différente : un modèle Transformer dédié à l’analyse des flux financiers haute fréquence. Cette architecture repose sur l’auto-attention multi-tête (multi-head self-attention), permettant de capturer efficacement les dépendances longues entre observations.
Architecture du modèle Transformer
Mon implémentation du Transformer a été réalisée sous PyTorch, avec une architecture optimisée pour les données séquentielles financières :
- Encodage des entrées :
- Embedding pour les variables catégoriques (venue, action, side).
- Convolution 1D sur les variables continues pour extraire des patterns locaux avant l’encodeur Transformer.
- Ajout d’un Positional Encoding basé sur sinus/cosinus pour préserver l’ordre temporel.
- Transformer Encoder :
- 6 couches d’attention multi-tête (8 heads) pour capturer différentes relations dans la séquence.
- Feedforward Network (FFN) à deux couches avec activation GELU.
- Résidual connections et Layer Normalization pour stabiliser l’apprentissage.
- Classification :
- Ajout d’un token [CLS] pour agréger les informations globales.
- Passage en MLP (Multi-Layer Perceptron) pour la prédiction finale.
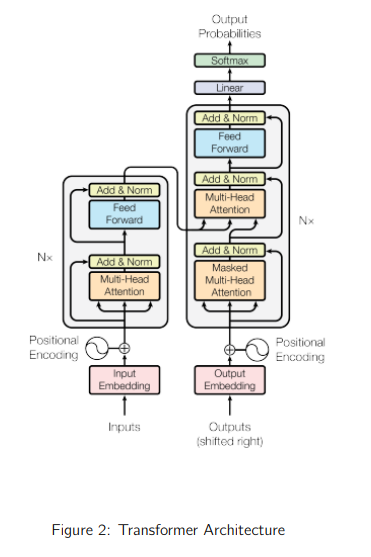
Mon implémentation s’inspire des études pionnières sur les Transformers, notamment Attention Is All You Need, qui a jeté les bases de cette architecture innovante. J’ai donc adopté une structure similaire, en l’adaptant aux besoins spécifiques de mon projet afin d’améliorer son efficacité et sa pertinence.
Optimisation et entraînement
- Fonction de perte : Cross-Entropy Loss adaptée aux problèmes multi-classes.
- Optimiseur : AdamW avec scheduler de learning rate pour éviter la divergence.
- Early stopping : Arrêt automatique après 107 epochs, critère de convergence basé sur l’évolution de la loss sur le dataset de validation.
Résultats et Comparaison avec les Approches Précédentes
L’utilisation du Transformer a permis une avancée majeure avec :
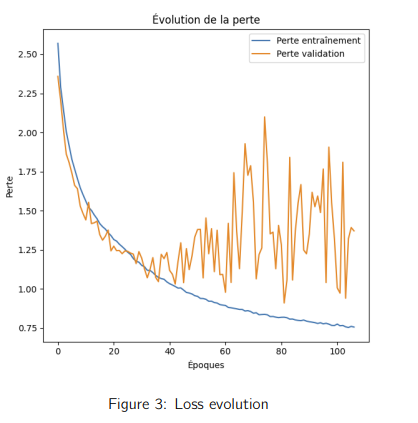
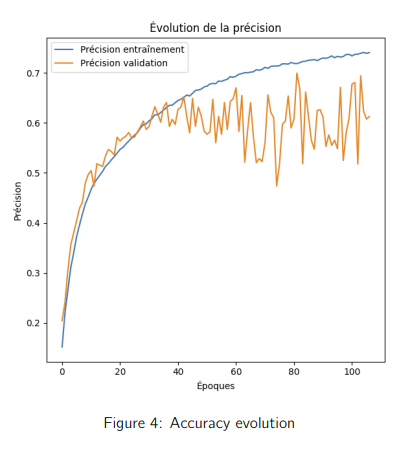
- 74% de précision sur l’ensemble d’entraînement.
- 61% sur l’ensemble de validation, surpassant de +6 points la meilleure approche en ensemble learning.
Bien que le modèle présente une légère instabilité après 35 epochs (overfitting potentiel), il démontre la puissance des Transformers pour les séries temporelles financières, ouvrant la voie à des applications plus avancées en prédiction de marché et trading algorithmique.
Résultat:
Après tous ces efforts, il est enfin temps de découvrir mon classement. Je me place 31ᵉ sur environ 180 participants, un résultat honorable pour une première participation à un défi de ce genre. Cette expérience m’a donné envie d’en relever d’autres !
Conclusion et Perspectives
Ce projet a constitué une expérience technique avancée, combinant :
- Manipulation de données massives et prétraitement avancé.
- Optimisation d’algorithmes d’ensemble learning (XGBoost, LightGBM, Bagging, Stacking).
- Déploiement d’un modèle Transformer pour l’analyse de flux financiers haute fréquence.
- Utilisation d’outils avancés d’optimisation et d’hyperparameter tuning (Optuna, AdamW, scheduler de LR).
L’intégration des Transformers en finance quantitative représente une avancée significative, s’inspirant des LLM pour améliorer la modélisation des dynamiques de marché. Mon ambition est désormais de poursuivre ces recherches en explorant les architectures hybrides combinant Transformers et séries temporelles pour affiner la prédiction des tendances boursières.


